모노레포 하나에 15개 서비스를 담은 이유
서비스는 마이크로서비스로 잘게 나누면서, 레포는 하나로 유지한 이유를 정리합니다.
지난 반년 동안 백엔드 서비스를 15개까지 늘렸습니다. 하지만 레포는 끝까지 하나로 두었습니다. 서비스마다 레포를 두는 방식이 일반적이지만, 저는 그 반대를 택했습니다.
서비스를 나눈 이유
목표는 단순했습니다. 한 서비스가 한 가지 일만 하도록 만드는 것입니다.
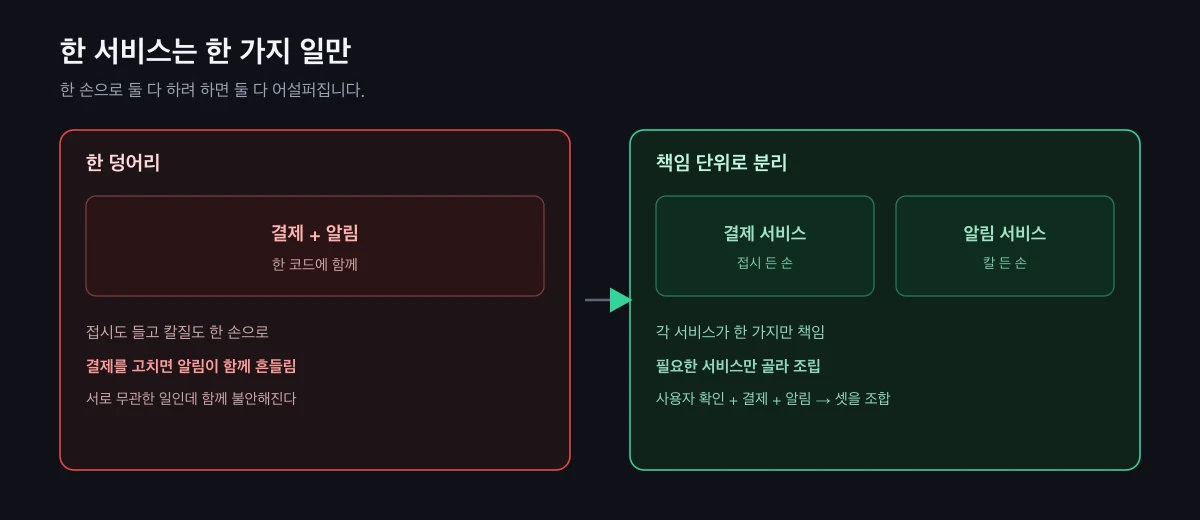
손에 비유해 보겠습니다. 한 손은 접시를 들고, 다른 손은 칼을 쥡니다. 한 손으로 둘 다 하려고 하면 둘 다 어설퍼집니다. 접시가 흔들리면 칼질이 흔들리고, 칼을 갈면 접시를 놓칩니다. 서로 무관한 일인데 한 덩어리라서 함께 흔들리는 것이지요.
서비스도 마찬가지입니다. 결제와 알림을 한 코드에 두면, 결제를 고칠 때마다 알림이 함께 불안해집니다. 그래서 책임 단위로 나누었습니다. 결제는 결제 서비스, 알림은 알림 서비스. 각 서비스가 무엇을 책임지는지 경계를 분명히 그었습니다.
경계를 그으면 이점이 하나 더 생깁니다. 필요한 서비스만 골라 조립할 수 있다는 점입니다. 새 기능에 "사용자 확인 + 결제 + 알림"이 필요하면 세 서비스를 조합하면 됩니다. 처음부터 다시 만들 필요가 없습니다.
이것이 마이크로서비스를 택한 이유입니다. 책임의 경계를 명확히 긋고, 그 조각을 필요에 따라 조립하기 위해서입니다.
레포는 나누지 않은 이유
보통은 여기서 레포도 함께 나눕니다. 서비스마다 레포 하나씩 두는 방식이지요.
다만 소수 인원에게는 이 방식이 불리한 것 같습니다. 서비스는 15개인데 다루는 사람은 몇 명이라, 한 명이 하루에도 여러 서비스를 동시에 만집니다. 레포가 흩어져 있으면 다음 문제가 반복됩니다.
- 서비스 A의 응답 형식을 바꾸면, 이를 사용하는 B·C까지 레포 세 곳에 PR을 올려야 합니다. 셋이 따로 병합되는 순간 서로 맞지 않는 구간이 생깁니다.
- 공통 코드 한 줄을 고치려고 버전을 올려 배포하고, 사용하는 쪽마다 다시 받아옵니다.
- 개발 서버에 어떤 버전 조합이 떠 있는지 한눈에 알기 어렵습니다.
그래서 코드는 한곳에 모았습니다. 서비스는 나누되, 코드는 한 레포에 두는 방식입니다.
backend/
├── apps/ # 서비스당 디렉토리 1개
│ ├── account/ # 인증/사용자
│ ├── billing/ # 결제
│ ├── notification/ # 알림
│ ├── ... # 도메인 서비스들
│ └── worker-*/ # 비동기 워커
├── packages/ # 공유 라이브러리
│ ├── shared/ # 공통 코드 (DB, 예외, 스키마)
│ ├── grpc-pb/ # 서비스 간 통신 규약
│ └── grpc-client-*/ # 서비스별 클라이언트
└── pyproject.toml # 워크스페이스 루트
한곳에 모으면 공통 코드를 고쳤을 때 사용하는 서비스가 즉시 같은 코드를 봅니다. 버전을 올리고 배포하고 다시 받아오는 왕복이 사라집니다. 통신 규약을 바꿔도 보내�는 쪽과 받는 쪽이 한 번에 함께 바뀝니다. 둘이 어긋난 채로 병합될 일이 없습니다.
한 레포여도 한 덩어리는 아닙니다
가장 흔한 오해입니다. 레포가 하나여도 서비스는 한 덩어리가 아닙니다. 코드를 같은 위치에 둘 뿐, 실행 시점에는 여전히 독립적으로 동작합니다.
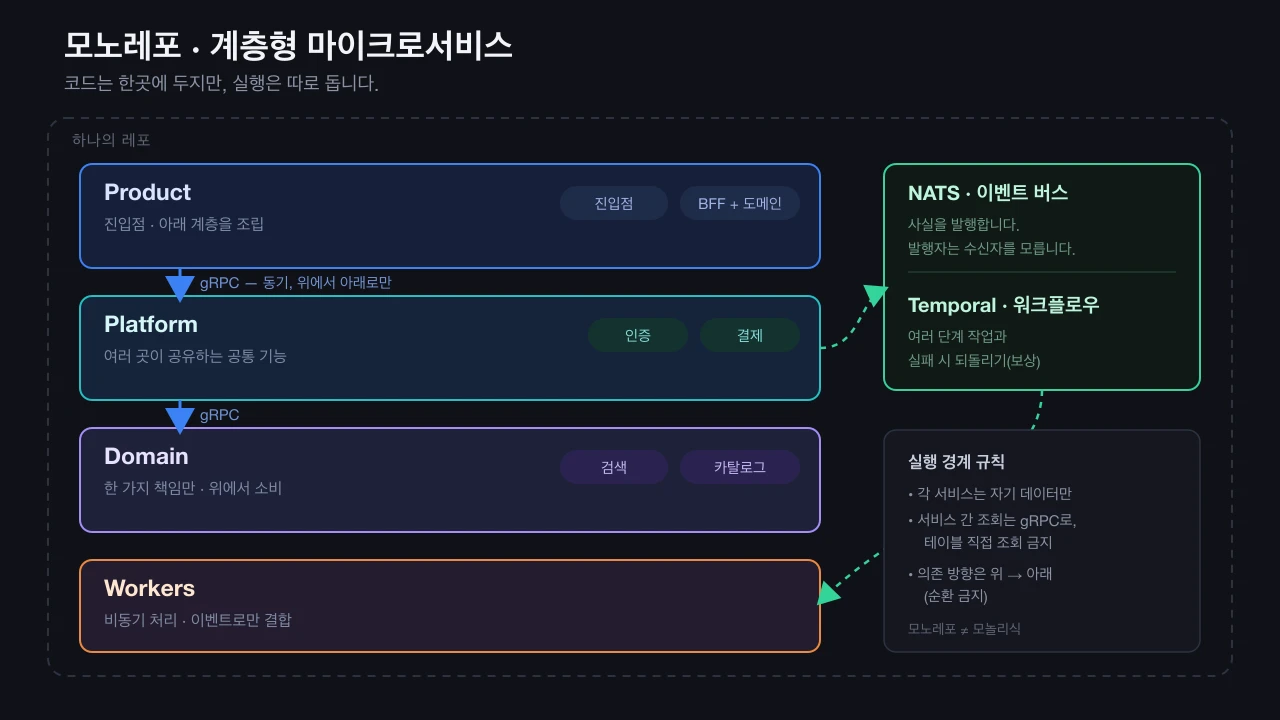
독립 실행을 지키기 위해 규칙을 정했습니다.
- 데이터는 각자만: 각 서비스는 자기 데이터만 직접 다룹니다. 남의 데이터가 필요하면 해당 서비스에 요청합니다. 남의 테이블을 직접 조회하는 것은 금지입니다.
- 호출은 정해진 통로로: 서비스 간 직접 호출은 gRPC를 씁니다. 형식이 정해져 있어 어긋나면 곧바로 드러납니다.
- 알림은 이벤트로: "결제 완료" 같은 사실은 이벤트로 발행합니다(NATS). 발행하는 쪽은 수신자를 모릅니다. 필요한 서비스가 알아서 받습니다.
- 긴 작업은 워크플로우로: 중간에 실패하면 되돌려야 하는 작업은 Temporal에 맡깁니다. 되돌리는 로직을 직접 짜면 단계를 빠뜨리기 쉽습니다.
서비스가 늘면 "이 코드를 어디에 둘지"가 부담이 됩니다. 그래서 위치를 네 계층으로 고정했습니다.
| 계층 | 역할 |
|---|---|
| Product | 클라이언트가 직접 호출하는 진입점. 아래 계층을 조립 |
| Platform | 여러 곳이 공유하는 공통 기능 (인증·결제 등) |
| Domain | 한 가지 책임만 가지는 서비스 |
| Workers | 뒤에서 도는 비동기 처리 |
규칙은 하나입니다. 호출 방향은 위에서 아래로만. 아래 계층이 위를 호출하면 서로 물려서 금세 엉킵니다. 진입점 계층은 단순 중계가 아니라 자기 로직을 가지며 아래를 조립하는 자리라, 이 한 방향 규칙이 특히 중요합니다.
새 서비스 추가도 단순해집니다. 잘 만든 서비스를 본떠 같은 구조(api / grpc / logic / model / schema)를 복사하면 됩니다. 만드는 방식이 옆 서비스에 그대로 남아 있는 셈입니다.
헬스체크에서 데인 대가
장점만 있지는 않았습니다. 코드를 한곳에 모으니 한 서비스의 실수가 옆으로 번지기 쉬워졌습니다. 가장 크게 데인 곳이 헬스체크입니다.
배포 시스템이 서비스 상태를 HTTP /health로만 확인하고 있었습니다. 그런데 우리 서비스는 HTTP 서버와 gRPC 서버를 한 프로세스에서 함께 띄웁��니다. gRPC 서버가 죽어도 HTTP /health는 정상으로 응답했습니다. 시스템은 해당 서버를 정상으로 판단하고 트래픽을 계속 보냈고, 그쪽으로 간 gRPC 요청은 모두 실패했습니다.
문제는 정상 서버와 섞여 있어 실패율이 100%가 아니라 어중간했다는 점입니다. "죽었다"가 명확히 보이지 않는 장애가 가장 오래 갑니다.
원인은 분명했습니다. "살아 있는가"의 기준이 실제 처리 능력과 어긋나 있었던 것입니다. 헬스체크는 "포트가 열렸는가"가 아니라 "요청을 받을 수 있는가"를 답해야 합니다. 서버를 둘 띄웠다면 답도 둘이어야 합니다.
해결은 두 가지였습니다.
- gRPC 서버도 상태를 별도로 응답하게 했습니다. 배포 시스템이 gRPC 쪽도 직접 확인하도록 한 것입니다.
- 종료를 단계적으로 처리했습니다. 종료 신호를 받으면 먼저 "수신 중단"으로 전환해 새 요청을 끊고, 처리 중인 요청을 마친 뒤 내려갑니다. 이 과정이 없으면 배포할 때마다 에러가 튑니다.
async def serve() -> None:
server = aio.server(...)
add_servicer_to_server(servicer, server)
health_servicer = register_health_servicer(server) # 반환값 보관 필수
server.add_insecure_port(listen_addr)
await server.start()
# 종료 신호 → "수신 중단" → 남은 요청 처리 → 종료
await wait_for_termination_with_graceful_shutdown(server, health_servicer)
포트도 전 서비스에서 통일했습니다. 초기에는 서비�스마다 포트가 달라 게이트웨이 설정이 복잡했습니다. 지금은 모든 서비스가 같은 포트를 쓰고, 게이트웨이는 경로로만 분기합니다. "이 서비스 포트가 무엇이었지"라는 질문이 사라졌습니다.
언제 다시 레포를 나눌까
모노레포가 항상 정답은 아닙니다. 지금 규모에 맞는 선택일 뿐입니다. 다음 신호가 보이면 분리를 다시 검토할 생각입니다.
- 특정 서비스나 팀이 나머지와 다른 속도로 배포해야 할 때.
- 빌드·테스트가 너무 길어져 피드백이 느려질 때.
- 코드 소유권을 팀별로 분명히 나눠야 할 때.
아직 그 시점은 아닌 것 같습니다. 그래서 한곳에 두고 있습니다.
마무리
- 서비스를 나눈 것은 책임의 경계를 긋고 필요에 따라 조립하기 위해서입니다.
- 레포를 나누지 않은 것은 소수 인원에게는 한곳에서 관리하는 비용이 더 낮기 때문입니다.
- 레포가 하나여도 서비스는 독립적으로 동작합니다. 데이터 격리 / gRPC / 이벤트 / 워크플로우로 경계를 지킵니다.
- 다만 한 서비스의 운영 실수가 옆으로 번집니다. 헬스체크처럼 한 프로세스가 서버 둘을 띄우는 지�점은 기준부터 다시 봐야 합니다.
다음 편에서는 이 위에 올린 인증을 다뤄 보겠습니다. 토큰 로그인을 붙이며 만난 무한 리다이렉트 루프, 그리고 쿠키 크기 한계가 설계를 어떻게 바꿨는지 적어 볼 생각입니다.