TSID vs UUID, 정렬 가능한 ID 만들기
기본키로 흔히 쓰는 UUID가 왜 DB 인덱스에 불리한지, 그리고 시간순으로 정렬되는 TSID로 무엇이 달라지는지 정리합니다.
결론부터 말하면, 시간순 정렬과 인덱스 성능이 필요하면 TSID(또는 UUIDv7), 단순 고유성만 필요하면 UUIDv4를 씁니다. 흔히 쓰는 UUIDv4는 무작위라 정렬이 안 되고 인덱스에 불리합니다.
TSID와 UUID, 무엇이 다른가
TSID(Time-Sorted ID)는 생성 시각을 앞부분에 담은 64비트 정수 ID로, 만든 순서대로 값이 커집니다. 반면 UUIDv4는 128비트 무작위 값이라 순서 정보가 없습니다.
도서관 책 번호에 비유할 수 있습니다. UUIDv4는 책마다 무작위 번호를 붙이는 것이고, TSID는 들어온 순서대로 번호를 붙이는 것입니다. 후자는 정렬과 "최근에 들어온 책 찾기"가 쉽습니다.
왜 정렬 가능한 ID가 중요한가
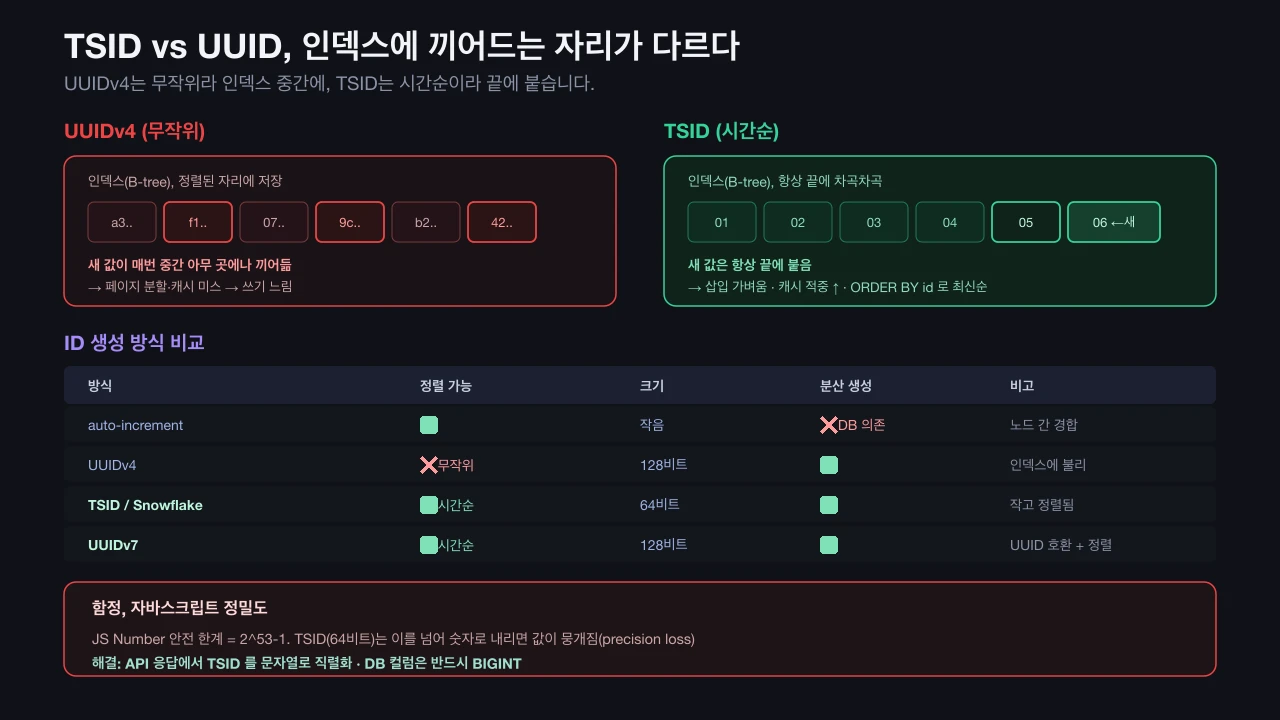
정렬 가능한 ID가 중요한 이유는 DB 기본키 인덱스(B-tree) 때문입니다. 인덱스는 값을 정렬된 순서로 저장하는데, 무작위 UUID는 매번 인덱스 중간 아무 �곳에나 끼어듭니다. 이러면 페이지 분할(page split)과 캐시 미스가 잦아져 쓰기 성능이 떨어집니다.
TSID처럼 값이 시간순으로 커지면, 새 값은 항상 인덱스 끝에 차곡차곡 붙습니다. 삽입이 가볍고 캐시 적중률도 높습니다. "최근 생성순 정렬"도 ORDER BY id만으로 됩니다(별도 created_at 정렬 불필요).
ID 생성 방식 비교
| 방식 | 정렬 가능 | 크기 | 분산 생성 | 비고 |
|---|---|---|---|---|
| auto-increment | ✅ | 작음 | ❌ (DB 의존) | 여러 노드에서 충돌·경합 |
| UUIDv4 | ❌ 무작위 | 128비트 | ✅ | 고유하지만 인덱스에 불리 |
| TSID / Snowflake | ✅ 시간순 | 64비트 | ✅ | 작고 정렬됨 |
| UUIDv7 | ✅ 시간순 | 128비트 | ✅ | UUID 호환 + 정렬 |
64비트면 충분하고 작은 키를 원하면 TSID, 표준 UUID 형식을 유지하면서 정렬도 원하면 UUIDv7이 좋은 선택입니다.
TSID 사용 방법
TSID는 생성과 저장이 단순합니다. 64비트 정수이므로 DB에는 BIGINT로 둡니다.
from tsidpy import TSID
new_id = TSID.create().number # 64비트 정수, 시간순 정렬
# SQLAlchemy 예시 (BIGINT 컬럼)
id: Mapped[int] = mapped_column(
BigInteger,
primary_key=True,
default=lambda: TSID.create().number,
)
흔한 함정 (자바스크립트 정밀도)
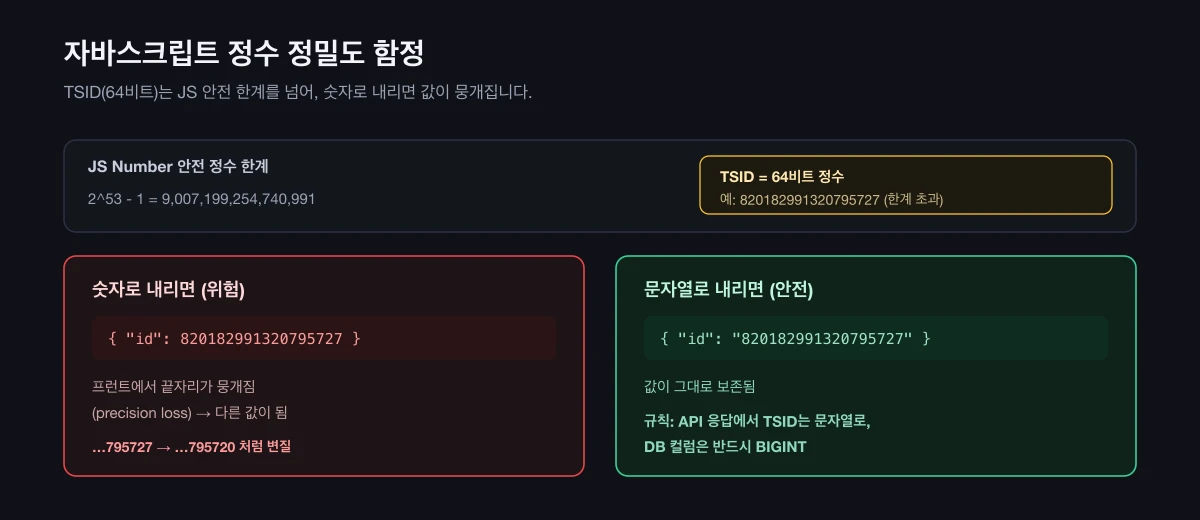
가장 자주 데이는 함정은 자바스크립트의 정수 정밀도입니다. JS의 Number는 안전 정수 한계가 2^53 - 1인데, TSID는 64비트라 이 한계를 넘습니다. 그대로 숫자로 내려보내면 프런트에서 값이 뭉개집니다(precision loss).
해결은 단순합니다. API 응답에서는 TSID를 문자열로 직렬화합니다.
// 숫자로 내리면 위험 → 문자열로
{ "id": "820182991320795727" }
그 외 주의점:
- 순차성 노출: 시간순이라 "다음 ID"를 추측당할 수 있습니다. 외부 노출 식별자가 추측되면 곤란한 경우, 별도 공개용 식별자를 둡니다.
- DB 컬럼 타입:
INT(32비트)로 두면 넘칩니다. 반드시BIGINT.
Q&A
- 그냥 auto-increment 쓰면 안 되나요?
- 단일 DB면 괜찮습니다. 다만 여러 서비스·노드에서 ID를 생성하면 DB에 의존하는 auto-increment는 충돌·경합이 생깁니다. TSID는 노드가 달라도 독립 생성됩니다.
- UUIDv7이 있는데 굳이 TSID인가요?
- 64비트로 작게 쓰고 싶을 때 TSID가 유리합니다. 표준 UUID 형식 호환이 중요하면 UUIDv7을 고르면 됩니다. 둘 다 "시간순 정렬"이라는 목적은 같습니다.
- 정렬되는 ID는 보안에 안 좋지 않나요?
- 추측 가능성이 있습니다. 내부 기본키로는 TSID를 쓰되, 외부에 그대로 노출하지 않거나 별도 공개 식별자를 두면 됩니다.
참고자료
- TSID / Snowflake ID 명세
- RFC 9562: UUID (UUIDv7 포함)